If an AI or machine learning model/algorithm is the publishable result of your study, you must consider its anonymity already during the development. You must be able to prove the anonymity of the model in order to publish it. Anonymity is assessed on a case-by-case basis.
When submitting a model for anonymity verification, you must also submit the Anonymity form for AI and machine learning models to Findata. You should read the form carefully already when planning the model, so that you are familiar with factors affecting anonymity already when developing the model.
Download the form: Anonymity form for AI and machine learning models (Word, 44 kb)
Anonymity is affected by:
- characteristics of the model itself (e.g. model type, number of parameters to be trained)
- features of the training data (e.g. such as quantity, content, format and possible processing, such as anonymisation)
- the model’s ability to generalise and how it performs the task for which it is trained.
If a model is trained exclusively on anonymous training material, the model itself can also be considered to be anonymous.
The anonymity of a model can be ensured by using differential privacy during training. There are no unequivocal guidelines for selecting the differential privacy parameters, as it depends on the situation and must be justified on a case-by-case basis.
Small values, such as
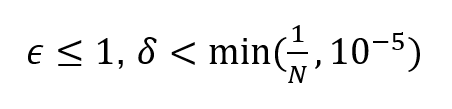
where N is the number of individuals in the material used, produce mathematically strong protection. However, in some cases, even higher values may suffice.
As a rule, training data should not include material containing individual-level direct identifiers. A model with parameters that include information referring to an individual in an understandable format (e.g. text) does not meet anonymity criteria. The development process must also include sufficient measures for assessing the generalisation ability of the model.