Jos tekoäly- tai koneoppimismalli/algoritmi itsessään on tutkimuksen julkaistava tulos, sen anonymiteettiin tulee kiinnittää huomiota jo kehitysvaiheessa. Mallin anonymiteetti tulee voida todistaa, jotta se voidaan julkaista. Jokaisen mallin anonymiteetti arvioidaan tapauskohtaisesti.
Kun malli toimitetaan anonymiteetin tarkastukseen, Findatalle tulee toimittaa myös tekoäly- ja koneoppimismallien anonymiteettilomake. Lomakkeeseen kannattaa tutustua huolellisesti jo mallin suunnitteluvaiheessa, jotta anonymiteettiin vaikuttavat tekijät voidaan huomioida jo kehitysvaiheessa.
Lataa lomake: Tekoäly- ja koneoppimismallien anonymiteettilomake (Word-tiedosto, 50,1 kt)
Anonymiteettiin vaikuttavat tekijät:
- Mallin ominaisuudet, kuten mallin tyyppi ja opetettavien parametrien määrä
- Mallin opetukseen käytetyn aineiston piirteet, kuten sen määrä, sisältö, muoto ja mahdollinen käsittely kuten anonymisointi
- Mallin yleistämiskyky ja suoriutuminen tehtävästä, jota varten se on koulutettu.
Jos mallia on koulutettu käyttäen ainoastaan anonyymia opetusmateriaalia, myös itse mallin voidaan katsoa olevan anonyymi.
Mallin anonymiteetti voidaan varmistaa käyttämällä sen koulutuksessa differentiaalista tietosuojaa. Käytettyjen differentiaalisen tietosuojan parametrien valintaan ei ole yksiselitteisiä ohjeita, vaan ne tulee määritellä tapauskohtaisesti ja valinta on perusteltava.
Pienet arvot kuten
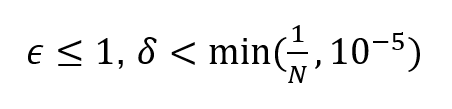
missä N on yksilöiden lukumäärä käytetyssä aineistossa, tuottavat matemaattisesti vahvan suojan, mutta tapauksesta riippuen myös suuremmat arvot saattavat riittää.
Pääsääntöisesti mallin opetusmateriaaliin ei tulisi sisällyttää aineistoa, joka sisältää yksilötasoisia suoria tunnisteita. Malli, jonka parametreihin on sisällytetty yksilöön viittaavia tietoja ymmärrettävässä muodossa (esimerkiksi tekstinä), ei täytä anonymiteetin kriteereitä. Mallin kehitysprosessissa tulee huomioida riittävät toimet mallin yleistämiskyvyn arviointiin.