På den här sidan hittar du anvisningar för att producera anonyma resultat samt exempel som kan stödja tillämpningen av anvisningarna. Längst ner på sidan hittar du instruktioner för att publicera resultaten i Kapseli eller i en annan informationssäker driftmiljö.
Innehåll
Inledning Vad betyder anonymisering? Beskrivande nyckeltal och analyser Diagram Övriga resultattyper Exempel som stöd för tillämpningen av anvisningen Hur kan man påskynda säkerställandet av anonymiteten hos de resultat som publiceras Publicering av resultaten Referensguide
Anvisningar för produktion av anonyma resultat
Inledning
Den som behandlar personuppgiftsmaterial ska producera resultaten i anonym form, så att en enskild persons uppgifter eller egenskaper inte avslöjas.
Findata säkerställer anonymiteten hos de resultat som publiceras. Detta gäller alla resultat som har producerats av material som har beviljats tillstånd med stöd av lagen om sekundär användning och som har behandlats i en datasäker driftmiljö enligt lagen om sekundär användning. Vi tar inte ut någon avgift för säkerställande av anonymitet.
Resultaten ska produceras så att de följer dessa anvisningar för olika typer av resultat. Målet är att säkerställa resultatens dataskydd.
Om resultaten inte kan produceras enligt dessa anvisningar, men producenten av resultaten bedömer att resultaten ändå är anonyma, ska motiveringar om anonymiteten lämnas till Findata på sammandragsblanketten som skickas med resultaten. Säkerställandet av anonymiteten för resultat som kräver individuell bedömning tar längre tid än normalt. De motiveringar som resultatproducenten lämnar till Findata ska gälla endast anonymiteten, inte till exempel vikten eller betydelsen av att publicera undersökningen eller resultaten för individen eller samhället.
Denna anvisning innehåller en lista över de vanligaste resultattyperna och risken för avslöjande i anslutning till dem. Förteckningen är inte uttömmande. Även materialets egenskaper och variablernas innehåll påverkar risken för avslöjande. För vissa resultattyper kan anonymiteten enkelt fastställas, medan det för andra krävs en noggrannare granskning. Den som producerar resultaten ska bedöma om definitionen av anonyma uppgifter uppfylls. Lämna inte in resultaten för säkerställande av anonymiteten innan du är säker på att resultaten har producerats i anonymt format!
Säkerställande av resultatens anonymitet består av:
- dessa anvisningar för Produktion av anonyma resultat
- en sammandragsblankett som skickas till Findata tillsammans med resultaten, samt
- inspektioner utförda av Findata.
Alla resultat som produceras i Kapseli måste exporteras från miljön med hjälp av Portti-verktyget för utdata. Portti är endast avsedd för att skicka in anonyma resultat för verifiering. Den får aldrig användas för att överföra personuppgifter eller annan icke-anonym information.
Vad betyder anonymisering?
Anonymisering innebär en process där materialet behandlas så att
- en enskild person inte kan identifieras direkt eller indirekt
- man inte kan dra slutsatser om endast en enskild identifierbar person
- uppgifter om denna person inte kan kombineras med annat material.
Anonymt material ska vara omöjligt eller orimligt svårt att återställa till en form där en enskild person kan identifieras.
Resultaten av material som utlämnats med stöd av lagen om sekundär användning ska vara anonyma (lagen om sekundär användning § 52). Om det i ett projekt finns behov av att publicera resultat som inte kan anonymiseras så ska detta beaktas redan när undersökningen planeras och möjligheten att genomföra projektet utifrån annan lagstiftning än lagen om sekundär användning övervägas.
Anonymiseringen ska genomföras enligt resultattypen, till exempel genom att använda tillräckligt grova klassificeringar, dölja, ändra eller radera uppgifter som medför risk för avslöjande, eller genom att öka osäkerheten i dem.
Även om ett enskilt resultat i sig är anonymt kan det genom att kombinera flera resultat vara möjligt att avslöja uppgifter om en enskild person. Ett typiskt exempel på detta är om flera frekvenstabeller som presenterar olika uppgifter produceras med samma klassificering av bakgrundsvariabeln. Från dessa tabeller kan det vara möjligt att kombinera en frekvenstabell med noggrannare uppgifter, som kan avslöja nya tilläggsuppgifter om tabellernas observationer.
Sammanställningen av resultaten ska beaktas både i den analys som är under arbete, i tidigare analyser och i kommande analyser. Om användaren känner till tidigare publikationer i vars analyser samma eller nästan samma material eller en del av det har använts, ska dessa resultat beaktas när risken för avslöjande bedöms.
För att säkerställa anonymiteten utgår man från att resultaten baserar sig på uppgifter från flera observationer och att minimifrekvensen i resultaten är tre. Resultaten, såsom uppgifterna i en tabells cell/grupp, ska basera sig på minst tre observationer.
Användningen av detta tröskelkriterium är ett tydligt och enkelt sätt att minska risken för avslöjande av enskilda personer och på så sätt säkerställa resultatens dataskydd. Resultatproducenten ska dock bedöma om detta är en tillräcklig minimifrekvens. Tröskelvärdet tre garanterar inte nödvändigtvis att resultaten är anonyma. Till exempel ska publicering av celler på 0 % och 100 % (alla eller ingen person har en viss egenskap) bedömas från fall till fall. Om en cell med liten cellspecifik frekvens är dold, ska man också säkerställa att det dolda värdet inte kan beräknas med hjälp av andra värden i tabellen.
Utöver den cellspecifika frekvensen ska storleken på den cellspecifika populationen beaktas. Den cellspecifika populationen hänvisar till de personer som kan höra till cellen i fråga på basis av egenskaper som definieras i resultaten (t.ex. personer i en viss ålder som bor i en viss kommun). En liten cellspecifik population ökar risken för identifiering av observationerna i cellen.
Findata behöver tillräckliga bakgrundsuppgifter för varje analystyp för att säkerställa anonymiteten. Ange dessa uppgifter, såsom det antal observationer som resultaten grundar sig på, i samband med resultaten eller på sammandragsblanketten som bifogas resultaten.
Beskrivande nyckeltal och analyser
Vid bedömningen av anonymiteten ska de principer som beskrivs i tabell 1 följas.
| Typ av resultat | Risk för avslöjande | Observationer |
|---|---|---|
| Beskrivande analyser och nyckeltal | ||
| Frekvenser | Oftast hög | Kan i regel publiceras när minimifrekvensen i resultaten är minst tre. Se även Exempel 1. |
| Maximi, minimi, variationsbredd | Oftast hög | Kan i regel publiceras när nyckeltalets värde grundar sig på flera observationer eller om avslöjandet av en individ kan förhindras på annat sätt. I allmänhet gäller minimi- och maximivärdet en enskild observation, så dessa värden kan medföra en risk för avslöjande. Resultatens anonymitet kan förbättras genom att dela in uppgifterna i klasser, vilket ger flera individer i varje klass. I stället för minimi och maximi kan man överväga att använda lämpliga kvantiler. Se även Exempel 2. |
| Fraktiler (kvantiler, deciler, percentiler, median) | Oftast hög | Kan i regel publiceras när antalet observationer som ligger bakom talet är tillräckligt stort. |
| Typvärde | Låg | Kan i regel publiceras om alla medlemmar i gruppen inte får samma värde. |
| Medelvärde, standardavvikelse | Oftast hög | Kan i regel publiceras, men kontrollera att resultatet beskriver en tillräckligt stor grupp och att hela målgruppen inte får samma värde. Dessutom ska man beakta att inga nyckeltal rapporteras för flera nästan identiska grupper eller delgrupper. |
| Index, relationstal, indikatorer | Låg | Kan i regel att publiceras, men den använda beräkningsformeln ska beaktas. Index i en mer komplicerad formel (t.ex. Fisher Price) medför i allmänhet ingen risk för avslöjande, men i mycket enkla formler är risken möjlig och det ska finnas tillräckligt med observationer bakom siffrorna. |
| Koncentrationsgrader | Låg | Kan i princip publiceras då det finns tillräckligt många observationer i gruppen. |
| Nyckeltal av högre moment (varians, kovarians, kurtosis, skevhet) | Låg | Kan i princip publiceras, eftersom nyckeltalet tydligt har modifierats från individens ursprungliga värden. Ska säkerställas att man inte publicerar för många nyckeltal från en liten grupp som kan leda till att hela gruppen avslöjas. |
| Diagram: presentation av originalmaterialet i bilder | Oftast hög | Se närmare observationer i avsnittet Diagram. |
| Korrelationer och analyser av regressionstyp | ||
| Regressionskoefficienter | Låg | Kan i princip publiceras. |
| Residualer vid estimering | Oftast hög | Residualerna hänvisar till en observation, vilket innebär en risk för avslöjande. Se närmare observationer i avsnittet Diagram. |
| Sammanfattnings- och teststatistik för estimat (t, F, R2, χ2 etc.) | Låg | Kan i princip publiceras då det finns tillräckligt många observationer i gruppen. |
| Korrelationskoefficienter | Låg | Kan i princip publiceras då det finns tillräckligt många observationer i gruppen. |
| Faktoranalys | Låg | Kan i princip publiceras, men man måste säkerställa att faktorerna inte bara beror på en enskild variabel. |
| Huvudkomponentanalys | Låg | Huvudkomponentvektorer och motsvarande egenvärden kan i princip publiceras. Observationernas projektioner för huvudkomponenterna ska kontrolleras, eftersom de motsvarar spridningsdiagram). Se närmare observationer i avsnittet Diagram. |
| Korrespondensanalys | Låg | Kan i princip publiceras. |
Med gruppen eller målgruppen avses de observationer från vilka nyckeltalen räknas.
Diagram
Utgångspunkten är att vid en bedömning av diagrammens dataskydd är en aggregerad presentation i tabellform lättare att uppfatta än själva diagrammet, eftersom det i allmänhet är omöjligt att se frekvensen av de observationer som ligger bakom varje punkt eller kurvan i diagrammet. Vid behov ska tabellen bakom resultatet bifogas diagrammet, om den beskriver enskilda observationer eller en liten målgrupp.
Fördelningsdiagram, histogram
I fördelningsdiagram ska särskild uppmärksamhet fästas vid avvikande observationer som kan medföra en risk för avslöjande. Detta kan medföra en utmaning särskilt för till exempel normalfördelningens svansar, och därför är det är möjligt att hela svansen inte kan avbildas. I histogrammen ska uppmärksamhet fästas vid att materialet har klassificerats så att det finns tillräckligt med observationer i en enskild klass. Jämför med anvisningen gällande nyckeltal som beskriver materialet.
Stapeldiagram
I stapeldiagram ska man fästa uppmärksamhet vid att det finns tillräckligt med observationer i varje klass. Jämför med anvisningen gällande nyckeltal som beskriver materialet.
Spridningsdiagram
I spridningsdiagram finns i regel en enhet bakom en punkt och därför är dessa inte publicerbara utan att materialet som använts för att producera diagrammet grupperats så att det finns flera observationer bakom en punkt. Spridningsdiagram får publiceras endast om de data som ligger till grund för diagrammet kan publiceras som en tabell. I bedömningen ska man dock också beakta om kombinationen av de använda variablerna gör det möjligt att identifiera en individ. Anonymiteten i spridningsdiagrammet kan förbättras genom att ersätta den med ett diagram som visar observationsfrekvensen i rutfältens celler eller genom att lägga till slumpmässighet i punkterna.
Lådagram, låddiagram (Box plot)
Lådagram medför i regel en risk för avslöjande, eftersom de innehåller bildpunkter för en enskild observation. I synnerhet avvikande observationer kan medföra risk för avslöjande. Även medeltalet kan medföra en risk för avslöjande. Jämför med anvisningen gällande nyckeltal som beskriver materialet.
Residualer
Residualer hänvisar till en observation. Vid beskrivning av residualer bör diagrammets form användas i stället för ett diagram som baserar sig på enskilda punkter. Om man använder ett diagram som baserar sig på enskilda punkter bör man undvika att ange axlarnas värden.
Överlevnadsanalys, Kaplan-Meier-diagram
En överlevnadsanalys kan orsaka en risk för avslöjande beroende på analysens specifikation. Utgångspunkten är att resultaten kan publiceras om varje steg i diagrammet motsvarar tillräckligt många observationer. Om det står klart att man med hjälp av uppgifterna bakom diagrammet inte kan dra en slutsats om exakt ålder eller kalendertidpunkter, kan även enskilda steg tillåtas. När enskilda steg publiceras måste man dock fundera på hur väl diagrammets bakgrundsuppgifter identifierar personer. Se även Exempel 3.
Spatial analys
Spatial analys är särskilt utmanande med tanke på dataskyddet, eftersom lokaliseringsuppgifter i allmänhet är centrala för individens avslöjande. Publiceringen av resultaten av den spatiala analysen kräver i allmänhet mycket omklassificering och presentation av information som värmekartor i stället för observationspunkter.
Sankey-diagram
Sankey-diagrammens, dvs. flödesdiagrammens, dataskydd påverkas av vilka uppgifter som visas i diagrammet. Om diagrammet beskriver exakta antal är anvisningen jämförbar med fallet med nyckeltal som beskriver materialet. Se även Exempel 4.
Övriga resultattyper
Bilder och annat bildmaterial
I fråga om bildmaterial ska situationen bedömas från fall till fall. Materialet får inte innehålla identifierings- eller metadata som hänvisar till en enskild person. Identifieringsrisken kan minskas genom begränsningar och genom att minska upplösningen. Om det går att kombinera annan data med bildmaterialet ökar detta risken för identifiering.
Mer information om anonymisering och anonymitet av bild- och signaluppgifter finns i riktlinjerna som utarbetats av en expertgrupp på hög nivå som tillsatts av social- och hälsovårdsministeriet: Anonymisering av bild- och signaluppgifter och anonymitet vid behandling enligt lagen om sekundär användning av social- och hälsovårdsuppgifter (stm.fi, PDF 248kB)
Resultat som baserar sig på genominformation
Anonymiteten hos resultat som baserar sig på genominformation bedöms alltid från fall till fall.
1. Sällsynta enskilda genetiska variationer
Det är i princip möjligt att publicera betydande sällsynta genetiska fynd om fyndet förekommer hos fler än tre undersökta personer. Om den genetiska variationen förekommer hos färre än tre undersökta personer, ska exakta uppgifter om antal till exempel döljas. När resultaten publiceras ska man fästa särskild uppmärksamhet vid deltagarnas identifierbarhet och från fall till fall bedöma om det räcker att använda minimifrekvensen n=3 för att förhindra att deltagarna identifieras. Ju mindre målgrupp som undersöks och ju mer bakgrundsuppgifter som berättas om deltagarna, till exempel om sjukdomens egenskaper (fenotypen) eller om det geografiska område från vilket målgruppen har samlats in, desto mer ökar de undersökta personernas identifierbarhet. Enskilda undersökta deltagares exakta ålder, exakt beskrivning av deltagarens egenskaper, sjukdomshistoria, exakta geografiska område från vilket deltagarna har samlats in eller annan information som äventyrar den undersöktas anonymitet får inte offentliggöras.
Uppgifter om egenskaperna hos genetiska variationer kan presenteras om dessa uppgifter redan finns i offentliga variantdatabaser för varianten i fråga (till exempel frekvensuppgifter om en allel, variantens kliniska betydelse, variantens identifierande rs-nummer eller undersökningsmetod med vilken det genetiska fyndet har upptäckts).
Sällsynta genetiska fynd kan publiceras till exempel enligt tabell 2.

2. Genetiska variationer som inte förekommer i den undersöktas egen arvsmassa
Tidsbundna genetiska mutationer som inte förekommer i den undersöktas egen arvsmassa utan förekommer till exempel i en cancertumör kan publiceras patientspecifikt. När resultaten publiceras ska dock särskild uppmärksamhet fästas vid risken för identifiering av enskilda personer. För enskilda personer får man inte publicera exakt ålder, exakt beskrivning av personens egenskaper, sjukdomshistoria, exakt geografiskt område där målgruppen har samlats in eller annan information som äventyrar personens anonymitet. Om det är möjligt att klassificera mutationer eller personer i grupper ska resultaten i första hand presenteras i denna form.
3. Släktforskning
När resultaten publiceras ska särskild uppmärksamhet fästas vid anonymiteten hos personer i släkten. Ärftliga genetiska förändringar som framkommer i en släktforskning kan publiceras och presenteras till exempel som släktträd enligt figur 1. Det är inte tillåtet att presentera andra exakta bakgrundsuppgifter om personer som förekommer i släktträdet, såsom ålder, tidpunkt då genetiska förändringar har hittats, geografiskt område där släkthistoria har samlats in eller annan information som äventyrar släktens anonymitet. Ju mer uppgifter om enskilda personer som visas i diagrammet, desto större blir risken för avslöjande. När det gäller mycket sällsynta sjukdomar är det möjligt att släktträd inte kan publiceras i anonym form.

Modeller för artificiell intelligens och maskininlärning
Om en modell eller algoritm för artificiell intelligens eller maskininlärning i sig är ett resultat som publiceras i undersökningen, ska man fästa uppmärksamhet vid modellens anonymitet redan under utvecklingen av modellen. Modellens anonymitet ska kunna bevisas för att den ska kunna publiceras. Varje modells anonymitet bedöms från fall till fall.
När modellen skickas för granskning av anonymiteten ska också en anonymitetsblankett för modeller för artificiell intelligens och maskininlärning skickas till Findata. Det är bra att bekanta sig noggrant med blanketten redan i modellens planeringsskede, så att de faktorer som påverkar anonymiteten är bekanta redan när modellen utvecklas.
Ladda ner blanketten: Anonymitetsblankett för modeller för artificiell intelligens och maskininlärning (Word-file, 53 kt)
Anonymiteten påverkas av 1) själva modellens drag, såsom typen av modell och antalet undervisningsparametrar, 2) egenskaperna hos det material som används i inlärningen av modellen, såsom dess mängd, innehåll, form och eventuell behandling, såsom anonymisering, samt 3) modellens generaliseringsförmåga och prestation i den uppgift för vilken den har tränats. Om modellen är utbildad med endast anonymt undervisningsmaterial kan också själva modellen anses vara anonym.
Modellens anonymitet kan säkerställas genom att använda differentiellt dataskydd i utbildningen. Det finns inga entydiga anvisningar för valet av parametrar för differentiellt dataskydd, utan det beror på situationen och valet måste motiveras. Små värden såsom
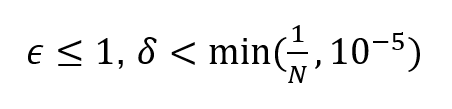
där N är antalet individer i det material som används, ger ett matematiskt starkt skydd, men beroende på fallet kan även större värden räcka.
I regel ska modellens undervisningsmaterial inte innehålla material som innehåller direkta identifierare på individnivå.En modell vars parametrar innehåller uppgifter som hänvisar till individen i begriplig form (till exempel i textform), uppfyller inte kriterierna för anonymitet. I utvecklingsprocessen bör man beakta tillräckliga åtgärder för att bedöma modellens generaliseringsförmåga.
Resultatmaterial på individnivå
Utgångspunkten är att resultaten som publiceras ska grunda sig på flera observationer. Om det finns behov av att publicera resultatmaterial som i sin helhet är på individnivå, ska resultatmaterialet uppfylla definitionen av anonym information (se även Vad betyder anonymisering?). För att producera anonymt material på individnivå behövs i allmänhet avancerade metoder, såsom differentiellt dataskydd. Anonymiteten hos material på individnivå ska alltid kontrolleras från fall till fall.
Syntetiskt resultatmaterial
Det syntetiska materialets anonymitet påverkas av syntetiseringsmetoden och egenskaperna hos det personuppgiftsmaterial som eventuellt används som underlagsmaterial. Att det publicerade materialet är syntetiskt räcker inte i sig till för att garantera dess anonymitet. Påvisandet av anonymiteten är starkt beroende av hur materialet produceras och hur komplicerat det är. Om avsikten är att skapa anonyma syntetiska data är det bra att redan när processen utvecklas beakta hur anonymiteten kan verifieras. Det syntetiska resultatmaterialets anonymitet ska alltid kontrolleras från fall till fall.
Resultat av kvalitativ forskning
Resultaten från kvalitativa forskningsmetoder ska också vara anonyma och uppfylla definitionen av anonym information. Om möjligt bör man i resultaten som publiceras använda en minimifrekvens på tre för att säkerställa dataskyddet. Om detta inte är möjligt ska resultaten behandlas så att en enskild person inte direkt eller indirekt kan identifieras. Metoden för hur målgruppen bildats påverkar identifieringsrisken. Identifieringsrisken är större om målgruppen innehåller alla personer som uppfyller vissa kriterier jämfört med en situation där målgruppen har valts slumpmässigt eller genom urval.
I synnerhet i samband med publicering av textutlåningar ska producenten av resultaten försäkra sig om att utlåningen inte möjliggör identifiering av en enskild person eller händelse. Identifieringsrisken ökar om citatet innehåller detaljer om en enskild person eller händelse eller om det gäller ett sällsynt fenomen.
Mer information om anonymisering av kvalitativt material och anonymiseringsmetoder finns på Finlands samhällsvetenskapliga dataarkivs webbplats (fsd.tuni.fi).
Se även Exempel 5.
Exempel som stöd för tillämpningen av anvisningen
Exempel 1. Frekvenstabell och sekundärt avslöjande
I en frekvenstabell ska celluppgifterna basera sig på minst tre observationer. Om antalet observationer är mindre än så ska det exakta värdet döljas. Uppgifter som hänvisar till färre än tre observationer kan döljas till exempel med anteckningen ”<3”.
Det dolda värdet ska inte kunna räknas ut med hjälp av andra värden i tabellen. Om man med hjälp av de övriga värdena i tabellen kan avgöra det exakta värdet på den dolda frekvensen, ska även de andra värdena döljas.
Exempel 1.1.
I tabellen nedan är cellen År 3 en observation som grundar sig på färre än tre personer och som därför ska döljas.
| År 1 | År 2 | År 3 | Sammanlagt antal | |
| Grupp a, n | 0 | 12 | 1 | 13 |
Det räcker dock inte att enbart dölja ett litet observationsvärde, eftersom man med hjälp av andra talvärden kan räkna ut dess exakta värde. Man kan förhindra att ett litet observationsvärde beräknas genom att förgrova det totala värdet eller ett annat observationsvärde enligt det exakta värdet nedan. Då kan man med hjälp av cellerna År 2 och Totalt antal dra slutsatsen att cellen År 3 kan få värdet 1 eller 2, men att det exakta värdet inte är känt.
| År 1 | År 2 | År 3 | Sammanlagt antal | |
| Grupp a, n | 0 | 12 | <3 | 13–14 |
| År 1 | År 2 | År 3 | Sammanlagt antal | |
| Grupp a, n | 0 | >10 | <3 | 13 |
Som utgångspunkt behöver nollvärdet inte döljas, eftersom uppgiften i fråga inte hänvisar till någon enskild person.
Exempel 1.2.
I tabellen nedan finns i två celler en observation som grundar sig på färre än tre personer (1), som båda ska döljas.
| År 1 | År 2 | År 3 | Sammanlagt antal | |
| Grupp b, n | 1 | 3 | 1 | 5 |
Även om båda observationsvärdena döljs med märkningen <3, kan man med hjälp av cellerna År 2 och Totalt antal dra slutsatsen att båda de dolda cellerna har värdet 1. I detta fall kan man förhindra att små observationsvärden kan räknas ut till exempel genom att dölja alla tre observationsvärden med märkningen <3.
| År 1 | År 2 | År 3 | Sammanlagt antal | |
| Grupp b, n | ≤3 | ≤3 | ≤3 | 5 |
Situationen skulle vara en annan om det totala antalet var till exempel 6 (såsom i tabellen 1.3. i exemplet nedan). Då skulle man inte ha kunnat avgöra vilken av de två dolda cellerna med märkningen <3 som får siffran 1 och vilken som får siffran 2.
Exempel 1.3.
Observationer som grundar sig på färre än tre personer kan också avslöjas med hjälp av relativa andelar. Även om små frekvenser döljs med <3 i exemplet nedan, kan man med hjälp av de relativa andelarna och totala antalet räkna ut de exakta värdena för cellerna År 1 och År 2.
| År 1 | År 2 | År 3 | Sammanlagt antal | |
| Grupp c, n | 1 | 3 | 2 | 6 |
| Grupp c, % | 17,7 | 50 | 33,3 | 100 |
I detta fall ska alltså även de relativa andelarna döljas.
| År 1 | År 2 | År 3 | Sammanlagt antal | |
| Grupp c, n | <3 | 3 | <3 | 6 |
| Grupp c, % | ≤33 | 50,0 | 17–33 | 100 |
Exempel 2. Minimi och maximi
Minimi- och maximivärdena gäller i allmänhet en enskild observation, så de kan innehålla en risk för avslöjande i synnerhet i fall där gruppens storlek är liten och/eller enskilda observationer är mycket avvikande. Minimi- och maximivärdena kan publiceras när nyckeltalets värde grundar sig på flera observationer eller när risken för att individen avslöjas kan förhindras på annat sätt.
När man till exempel presenterar nyckeltal för deltagarnas längd kan exceptionellt korta eller långa personer skilja sig från gruppen, varvid risken för att individen avslöjas ökar. I en grupp enligt tabellen nedan, där medellängden är 168 cm, skiljer sig siffervärdet för en person på 195 cm exceptionellt från gruppen. Människor kommer också lätt ihåg personer med exceptionella egenskaper, varvid risken för att personen i fråga avslöjas är större.
| Längd, cm | |
| Person 1 | 162 |
| Person 2 | 162 |
| Person 3 | 170 |
| Person 4 | 157 |
| Person 5 | 195 |
| Person 6 | 166 |
| Person 7 | 171 |
| Person 8 | 164 |
Resultatens anonymitet kan förbättras genom att dela in uppgifterna i klasser, vilket ger flera individer i varje klass. Vid sidan av minimi och maximi kan man överväga att använda lämpliga kvantiler.
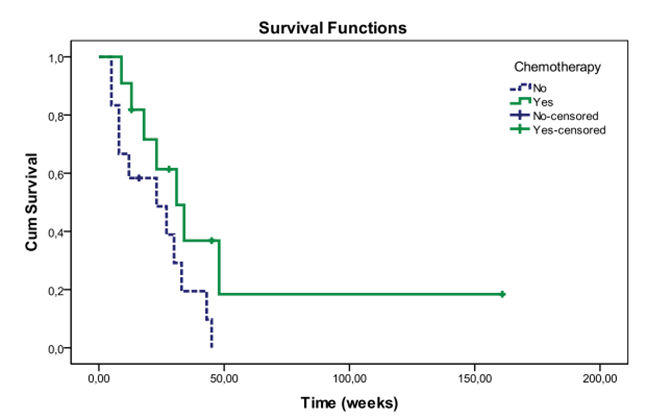
Exempel 3. Kaplan-Meier-diagram
Ett Kaplan-Meier-diagram och dess bakgrundsmaterial kan publiceras om man med hjälp av uppgifterna bakom diagrammet inte kan dra slutsatser om exakta kalendertidpunkter eller enskilda personers egenskaper, såsom ålder. Då kan även enskilda steg tillåtas i diagrammet. Diagrammet i figur 2 kan publiceras eftersom man utifrån det inte kan identifiera enskilda personer eller dra slutsatser om exakta kalendertidpunkter.
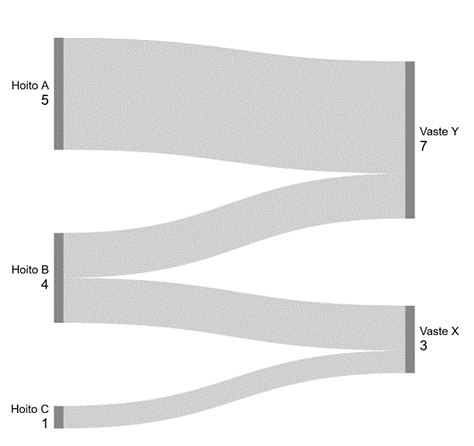
Exempel 4. Sankey-diagram
Om ett Sankey-diagram beskriver exakta antal ska minimifrekvensen beaktas i resultaten. Uppgifterna i figur 3 kan inte publiceras utan anonymisering, såsom omklassificering, eftersom exakta n<3 frekvenser framgår av diagrammet.
Exempel 5. Material och kvalitativ forskning på individnivå
Utgångspunkten är att resultaten som publiceras ska grunda sig på flera observationer. Detta gäller även kvalitativa undersökningar. Om det dock finns behov av att publicera resultatmaterial på individnivå ska resultaten behandlas så att enskilda personer inte kan identifieras i resultatmaterialet.
I synnerhet vid textutlåning ökar identifieringsrisken om utlåningen innehåller detaljer som gäller en enskild person eller händelse eller gäller ett sällsynt fenomen. I det fiktiva textcitatet nedan finns förutom patientens namn även mycket annan specificerande information.
13-åriga Eero Exempel fördes till Åbo universitetscentralsjukhus för vård efter att han fallit på Turun Yhteiskoulus gård. E.E. har hemofili A. Gastroenterologen som undersökte E.E skrev en remiss…
I textcitat kan detaljerna döljas genom kategorisering, varvid identifieringsrisken kan minskas.
[Patienten] [i högstadieålder] fördes till [universitetscentralsjukhuset] för vård efter att hen hade fallit på [skolans] gård. [Patienten] lider av [svår kronisk sjukdom]. [Läkaren] som undersökte [patienten] skrev en remiss…
Hur kan man påskynda säkerställandet av anonymiteten hos de resultat som publiceras
Produktion av anonyma resultat – checklista för producenten av resultaten
| Använd denna checklista som hjälp innan du lämnar in de resultat som ska publiceras för kontroll av anonymiteten. | Utfört ✓ |
| Jag har läst Findatas anvisning om produktion av anonyma resultat. | |
| Resultaten uppfyller definitionen av anonym information. | |
| Resultaten innehåller inga direkta identifierare (t.ex. namn, personbeteckning). | |
| Resultaten innehåller inga starka indirekta identifierare (t.ex. adress, registreringsnummer). | |
| Resultaten innehåller inga pseudonymiserade identifierarkoder (t.ex. Findatas FID). | |
| Resultaten innehåller inga cellvisa frekvenser n < 3. Om resultaten innehåller cellvisa frekvenser n < 3 har jag motiverat resultatens anonymitet. | |
| Om små frekvenser har maskeras kan de maskerade värdena inte härledas med hjälp av andra resultat. | |
| Resultaten innehåller inga uppgifter på individnivå eller uppgifter som hänför sig till en enskild person (t.ex. minimum, maximum). Om resultaten innehåller sådan information har jag motiverat resultatens anonymitet. | |
| Jag har bedömt resultatens anonymitet med särskild noggrannhet om resultaten innehåller: AI-/maskininlärningsmodell Bilder eller annat bildmaterial Genetisk eller genomisk information Syntetiskt resultatmaterial | |
| Jag har kontrollerat att inget data har blivit dolt i bakgrunden av resultatfilerna. Jag har fäst särskild uppmärksamhet vid R-filer (.rda, .rdata, .rds, .rdm), metadata i bildmaterial, Pythons Jupyter Notebooks (.ipynb) samt Excels dolda kalkylblad/flikar. |
Hur säkerställandet av resultatens anonymitet kan påskyndas
- Läs noggrant igenom anvisningarna på denna sida. Kontrollera att dina resultat följer anvisningarna.
- Fyll i sammandragsblanketten omsorgsfullt och beakta alla punkter på blanketten.
- Om dina resultat inte motsvarar alla påståenden, motivera varför resultaten ändå kan anses vara anonyma. Observera att sådana uppgifter inte kan publiceras utan giltiga motiveringar.
- Producera resultaten i en form som möjliggör säkerställande av anonymiteten.
- Säkerställ att alla variabler har beskrivits med namn som en utomstående person kan förstå.
- Se till att resultattypen framkommer tydligt (t.ex. frekvens, regressionskoefficient).
- Be om resultat från driftmiljön i ett paket av förnuftig storlek.
- Det lönar sig inte att leverera enskilda resultatpaket ofta (t.ex. varje dag). Behandlingen av resultatpaket som flera olika leveranser tar mer tid när det gäller överföring och kommunikation.
- Ett stort antal resultat förlänger granskningstiden. I regel rekommenderar vi att resultaten lämnas in i paket med högst 50 filer. Att hantera ett mycket stort resultatpaket med hundratals filer/flikar är arbetsamt, särskilt om det finns anmärkningar om anonymiteten i resultaten.
- Lämna in resultaten i ett filformat som är i allmänt bruk, såsom Word, pdf, Excel, csv, JPEG, TIFF eller PNG.
Källor
- Bond et al.: Guidelines for Output Checking
- Brandt et al. (2009): Guidelines for the checking of output based on microdata research (ec.europa.eu)
- European Data Protection Board: Opinion 28/2024 on certain data protection aspects related to the processing of personal data in the context on AI models.
- Griffiths, E. et al. (2019). Handbook on Statistical Disclosure Control for Outputs, version 1.0 2019.
- Hundepool, Anco; Domingo-Ferrer, Josep; Franconi, Luisa; Giessing, Sarah; Schulte-Nordholt, Eric; Spicer, Keith & de Wolf, Peter-Paul (2012). Statistical Disclosure Control.
- Ponomareva et al. (2023). How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy. Journal of Artificial Intelligence Research Vol. 77, 2023.
- SankeyMATIC (2024).
- Social- och hälsovårdsministeriet: Pseudonymisointi, anonymisointi ja suorien tunnisteiden käyttö Sosiaali- ja terveystietojen toissijaisesta käytöstä annetun lain (522/2019) mukaan.
Publicering av resultaten
I detta sammanhang innebär publicering att föra information till allmänheten och sprida den till det omgivande samhället. Publicering definieras som presentation av resultat utanför din egen arbetsgrupp.
Publicering kan ske i en vetenskaplig eller annan tidskrift, avhandling, lärobok eller manual, konferens eller annan presentation, eller i ett abstrakt, rapport, recension eller någon form av internetpublikation.
Publicering resultat från Kapseli
Behandlingen av materialet sker i Kapseli-driftmiljön och endast färdiga analysresultat förs utanför systemet. Tillståndshavaren producerar resultaten i anonym form och Findata säkerställer resultatens anonymitet.
- Alla resultat som produceras i Kapseli måste exporteras från driftmiljön med hjälp av exportverktyget Portti.
- Portti är endast avsett för överföring av anonyma resultat. Det får aldrig användas för att överföra personuppgifter eller annan icke-anonym information.
- Anvisningar för hur man producerar anonyma resultat finns på Findatas webbplats: https://findata.fi/sv/tjanster-och-anvisningar/produktion-av-anonyma-resultat/
Överföring av resultat via Portti
- Öppna Portti
- Verktyget Portti finns på Kapselis skrivbord.
- Välj språk
- Klikp på ”SV” uppe till höger.
- Skapa en ny överföring
- Klicka på ” Ny resultatinlämning” uppe till vänster.
- Välj filer att överföra
- Klicka på ”Choose Files” och välj filen eller zip-mappen som innehåller resultaten.
- Endast en fil kan överföras åt gången. Om du vill överföra flera filer, komprimera dem först till en zip-mapp.
- Kontrollera att det inte finns något dolt material i bakgrunden av resultatfilen (t.ex. metadata).
- Kontrollera att filnamnet inte innehåller mellanslag eller specialtecken (/,?+)[). Tillåtna specialtecken är punkt, bindestreck och understreck (.-_).
- Den maximala storleken för en överföring är 20 MB.
- Fyll i den begärda informationen
- Fyll i den begärda informationen i avsnitten ”Resultat som ska lämnas in” och ”Sammanfattning”.
- Välj den eller de resultattyper som bäst beskriver dina resultat. Överföringen går inte vidare utan detta val. Du kan välja flera alternativ.
- Skicka resultaten
- Klicka på ”Submit”. Resultaten skickas till Findata för kontroll av anonymitet.
Behandling av överföringar och godkännande av resultat
- Tidsplan och kommunikation
- Findata behandlar resultaten inom fem arbetsdagar efter inlämning.
- Du kan följa statusen för dina överföringar i vyn ”Mina inlämningar” i Portti.
- Findata skickar meddelanden från adressen: portti@csc.fi
- När du svarar på e-postmeddelandet dirigeras ditt svar automatiskt till data@findata.fi, där Findatas personal läser det.
- Om anonymiteten behöver omprövas
- Du får ett e-postmeddelande med information om vilka ändringar som krävs.
- Gör ändringarna enligt anvisningarna och skicka en ny överföring via Portti.
- Godkännande av resultat
- När resultaten har godkänts överförs de till inlämnarens personliga Tunneli (tidigare Nextcloud). Du får ett automatiskt e-postmeddelande.
- Resultaten raderas automatiskt från Tunneli 6 månader efter överföringen, så kom ihåg att spara dem till din egen enhet i tid.
- Om ytterligare information om anonymitet behövs
- Findata kan begära mer information om resultatens anonymitet innan slutligt godkännande.
- Efter e-postväxlingen får du ett officiellt meddelande om antingen godkännande eller avslag av resultatens anonymitet.
Obs! Om resultatfilerna är mycket stora uppfylls inte nödvändigtvis tidsgränsen på 5 vardagar.
Publicering resultat från andra driftmiljöer
Om du behandlar data i en annan säker driftmiljö än Findatas Kapseli och är redo att publicera resultaten, följ instruktionerna nedan.
- Ladda ner sammanfattningsformuläret och fyll i den begärda informationen: Sammanfattningsformulär – verifiering av resultatens anonymitet (Word-fil, 38 kB).
- Komprimera filerna och sammanfattningsformuläret till en zip-mapp och namnge det enligt följande:
- “Resultaten_[Registreringsnummer_för_tillståndsbeslut]_[Driftmiljö_ID]_[Leverans_datum]” (e.g., “Resultaten_THL_1234_14.02.00_2020_a01_15032021”).
- Obs: skriv datumet i formatet ddmmyyyy.
- Du kan leverera resultaten till Findata på två sätt:
- Om du har ett Tunneli-konto, överför resultaten via Tunneli
- Om du inte har ett Tunneli-konto överför resultaten via säker e-post
- Obs! Skicka inte resultatfilerna till Findata som en bilaga till ett vanligt, osäkert e-postmeddelande.
- Kontakta Findata på data@findata.fi
- Namnge ämnet för ditt e-postmeddelande som ”Säkerställa resultatens anonymitet”
- Ange i din e-post om du överför resultaten via Nextcloud eller via säker e-post.
- Om du använder Tunneli, ange datatillståndets diarienumret och ditt Tunneli-ID. Findata ger dig namnet på mappen där du kan överföra dina resultat och en zip-mapp som innehåller sammanfattningsformuläret.
- Om du överför dina resultat via säker e-post får du ett säkert e-postmeddelande från Findata som du kan svara på att säkert överföra zip-mappen som innehåller dina resultat och sammanfattningsformuläret.
- För mer information om kryptering och dataöverföring via Tunneli, se sidan Skicka material till Findata.
- Om det finns några problem om resultatens anonymitet kommer vi att kontakta dig inom sju arbetsdagar efter att resultaten skickats in.
- Om du inte hör från oss inom sju arbetsdagar efter att du skickat in dina resultat kan du fortsätta med publiceringen av dina resultat.
Se tips om hur du kan påskynda processen för att verifiera anonymiteten för dina resultat högst upp på denna sida.
Referensguide
Om Findata har beviljat ett dataanvändningstillstånd för projektet eller fattat ett beslut om begäran om uppgifter, hänvisa till Findata i publikationerna enligt följande: ”Tillståndsmyndigheten för social- och hälsovårdsdata Findata” eller ”Finnish Social and Health Data Permit Authority Findata”.
- Följ skrivinstruktionerna för den vetenskapliga publiceringsserien.
- Vi rekommenderar att hänvisningar till Findata görs i enlighet med dess lagstadgade uppgifter. I dataanvändningstillstånd kan dessa exempelvis vara pseudonymisering och säkerställande av anonymiteten i resultaten, medan de i begäran om uppgifter kan vara sammanslagning av data, aggregering och anonymisering.
- Det går att hänvisa till Findata i texten, tabeller, bilder, tillståndsförteckningar, tacksektioner och referenslistor.
- Inkludera om möjligt diarienummer för dataanvändningstillstånd eller begäran om uppgifter i referenserna.
Exempel på referens i texten
”Forskningsdata erhölls från Tillståndsmyndigheten för social- och hälsovårdsdata Findata med dataanvändningstillstånd THL/XXXX/14.XX.00/20XX. Findata ansvarade för pseudonymiseringen av datan och säkerställandet av anonymiteten i resultaten.”
”The research data was obtained from Findata, the Finnish Social and Health Data Permit Authority, with data permit THL/XXXX/14.XX.00/20XX. Findata was responsible for the pseudonymization of the data and ensuring the anonymity of the final results.”
”Statistiken har producerats av Tillståndsmyndigheten för social- och hälsovårdsdata Findata genom en begäran om uppgifter THL/XXXX/14.XX.00/20XX. Findata ansvarade för sammanslagningen av datan och framtagningen av anonymiserad statistik.”
The statistics were produced by Findata, the Finnish Social and Health Data Permit Authority, with data request THL/XXXX/14.XX.00/20XX. Findata was responsible for data aggregation and producing the anonymized statistics.”
Exempel på referens i en tabell
| Data | Källa |
|---|---|
| Forskningsdata | Tillståndsmyndigheten för social- och hälsovårdsdata Findata, dataanvändningstillstånd THL/XXXX/14.XX.00/20XX |
Exempel på referens i referenslistan
Findata. (År). Dataanvändningstillstånd THL/XXXX/14.XX.00/20XX. Tillståndsmyndigheten för social- och hälsovårdsdata Findata.
Findata. (Year). Data permit THL/XXXX/14.XX.00/20XX. Finnish Social and Health Data Permit Authority Findata.