Tietoturvallisesta käyttöympäristöstä ulos tuotavat tulokset on tuotettava anonyymissa muodossa siten, ettei yksittäisen henkilön tietoja tai ominaisuuksia paljastu.
Tältä sivulta löydät ohjeet anonyymien tulosten tuottamiseen ja esimerkkejä ohjeen soveltamisen tueksi.
Sisällys
Johdanto Mitä anonymisointi tarkoittaa Kuvailevat tunnusluvut ja analyysit kuviot Muut tulostyypit Esimerkkejä ohjeen soveltamisen tueksi Anonyymien tulosten tuottajan tarkastuslista Lähteet
Ohje anonyymien tulosten tuottamiseen
Johdanto
Henkilötietoaineistoa käsittelevän luvansaajan on tuotettava tutkimustulokset anonyymissa muodossa siten, ettei yksittäisen henkilön tietoja tai ominaisuuksia paljastu.
Luvansaaja anonymisoi tietoturvallisesta käyttöympäristöstä ulos tuotavat tulokset ja Findata varmistaa tulosten anonymiteetin riskiperusteisen arvioinnin perusteella.
Lue lisää: Tulosten tuominen ulos käyttöympäristöstä
Anonymiteetin varmistuksesta ei peritä maksua.
Tulokset on laadittava siten, että ne noudattavat tätä ohjeistusta eri tulostyyppien osalta. Anonyymien tulosten tuottamisen tavoitteena on varmistaa tulosten tietosuoja.
Tämä ohje sisältää listan yleisimmistä tulostyypeistä ja niihin liittyvästä paljastumisriskistä. Lista ei ole kattava, ja paljastumisriskiin vaikuttavat myös aineiston ominaisuudet ja muuttujien sisältö. Joidenkin tulostyyppien anonymiteetti voidaan todeta helposti, kun taas toiset vaativat tarkempaa arviointia.
Tulosten anonymiteetin varmistaminen koostuu seuraavista osa-alueista:
- Findatan anonyymien tulosten tuottaminen -ohje
- Luvansaajan täyttämä riskiarvio
- Findatan suorittama varmistus riskiperusteisen arvioinnin perusteella
Mitä anonymisointi tarkoittaa?
Anonymisointi tarkoittaa prosessia, jossa aineisto käsitellään niin, että
- yksittäistä henkilöä ei voida tunnistaa suoraan tai välillisesti
- yksittäistä tunnistettavaa henkilöä koskevia päätelmiä ei voida tehdä
- yksittäistä henkilöä koskevia tietoja ei voida yhdistellä muuhun aineistoon.
Anonyymi aineisto tulee olla mahdotonta tai kohtuuttoman vaikeaa palauttaa muotoon, jossa yksittäinen henkilö on tunnistettavissa.
Toisiolain perusteella luovutetuista aineistoista tuotettujen tulosten on oltava anonyymejä (toisiolaki §52). Jos tutkimuksessa on tarve julkaista tuloksia, joita ei ole mahdollista anonymisoida, tulee tämä huomioida jo tutkimuksen suunnitteluvaiheessa. Tällöin tulee harkita, onko mahdollista toteuttaa tutkimus perustuen muuhun lainsäädäntöön kuin toisiolakiin.
Tulokset on anonymisoitava tulostyypin mukaisesti. Tämä voidaan tehdä esimerkiksi:
- käyttämällä tarpeeksi karkeita luokituksia,
- peittämällä, muuttamalla tai poistamalla tietoja, joihin liittyy paljastumisriski, tai
- lisäämällä tietoihin epävarmuutta.
Vaikka yksittäinen tulos itsessään olisi anonyymi, useiden tulosten yhdisteleminen voi paljastaa yksittäistä henkilöä koskevia tietoja. Tyypillinen esimerkki tästä on useampien eri tietoja esittävien frekvenssitaulukoiden tuottaminen samoilla taustamuuttujien luokituksilla. Näitä yhdistelemällä voi syntyä tarkempi frekvenssitaulukko, joka voi paljastaa uusia lisätietoja taulukoiden havainnoista.
Tulosten yhdisteleminen tulee huomioida sekä käynnissä olevissa analyyseissa että aiemmissa ja tulevissa analyyseissa. Jos olet tietoinen aiemmista julkaisuista, joiden analyyseissä on käytetty samaa tai lähes samaa aineistoa tai sen osajoukkoa, huomioi nämä tulokset paljastumisriskiä arvioidessa.
Anonymiteetin varmistamiseksi lähtökohtana on, että tulokset perustuvat useamman havainnon tietoihin, ja tuloksissa esiintyvä minimifrekvenssi on kolme.
Tämä tarkoittaa, että esimerkiksi taulukon solun tai ryhmän tietojen on pohjauduttava vähintään kolmeen havaintoon.
Minimifrekvenssi-kynnysarvon käyttö on selkeä ja yksinkertainen tapa vähentää yksittäisten henkilöiden paljastumisriskiä ja varmistaa tulosten tietosuoja. Tulosten tuottajan on kuitenkin arvioitava, onko minimifrekvenssi riittävä, sillä sen täyttäminen ei aina takaa anonymiteettia.
Esimerkiksi 0 % ja 100 % -solujen (kaikilla tai ei yhdelläkään henkilöllä on tietty ominaisuus) julkaiseminen edellyttää tapauskohtaista harkintaa. Jos pienen solukohtaisen frekvenssin sisältävä solu on peitetty, on myös varmistettava, ettei peitettyä arvoa päätellä taulukon muiden lukujen avulla.
Solukohtaisen frekvenssin lisäksi on huomioitava solukohtaisen perusjoukon koko. Solukohtainen perusjoukko viittaa niihin henkilöihin, jotka voisivat kuulua kyseiseen soluun tuloksissa määriteltävien ominaisuuksien perusteella (esim. tietyssä kunnassa asuvat tietyn ikäiset henkilöt).
Pieni solukohtainen perusjoukko lisää soluun kuuluvien havaintojen tunnistamisen riskiä.
Arvioin tulosten olevan anonyymeja, mutta ne eivät noudata Findatan ohjeistusta
Jos et voi tuottaa anonyymejä tuloksia Findatan ohjeen mukaisesti, mutta arvioit niiden olevan anonyymeja, toimi seuraavasti:
- Toimita tulosten mukana yksityiskohtaiset perustelut anonymiteetistä. Perustelujen tulee koskea ainoastaan anonymiteettia, ei esimerkiksi tutkimuksen merkittävyyttä tai tulosten julkaisemisen tärkeyttä.
- Liitä mukaan riittävät taustatiedot kunkin analyysityypin osalta anonymiteetin arvioimiseksi. Näitä voivat olla esimerkiksi kuvaus tutkimusjoukon muodostamisesta sekä havaintomäärät.
Huomioi, että tapauskohtaisesti arvioitavien tulosten anonymiteetin varmistus voi kestää tavallista pidempään.
Kuvailevat tunnusluvut ja analyysit
Huomioi taulukossa kuvatut periaatteet, kun tuotat kuvailevia tunnuslukuja ja analyysituloksia anonyymissa muodossa.
| Tuloksen tyyppi | Paljastumisriski | Huomiot |
|---|---|---|
| Kuvailevat analyysit ja tunnusluvut | ||
| Frekvenssit | Yleensä korkea | Lähtökohtaisesti julkaistavissa, kun tuloksissa esiintyvä minimifrekvenssi on vähintään kolme. Kts. Esimerkki 1. |
| Maksimi, minimi, vaihteluväli | Yleensä korkea | Lähtökohtaisesti julkaistavissa, kun tunnusluvun arvo perustuu useampaan havaintoon tai yksilön paljastuminen voidaan estää muulla tavoin. Yleensä minimi ja maksimi kohdistuvat yksittäiseen havaintoon, joten nämä arvot voivat aiheuttaa paljastumisriskin. Tulosten anonymiteettiä voi parantaa jakamalla tiedot luokkiin, jolloin jokaiseen luokkaan tulee useampia yksilöitä. Minimin ja maksimin sijaan voi harkita sopivien kvantiilien käyttöä. Kts. Esimerkki 2. |
| Fraktiilit (kvantiilit, desiilit, persentiilit, mediaani) | Yleensä korkea | Lähtökohtaisesti julkaistavissa, kun luvun taustalla oleva havaintojen lukumäärä on riittävän suuri. |
| Moodi | Matala | Lähtökohtaisesti julkaistavissa, jos kaikki ryhmän jäsenet eivät saa samaa arvoa. |
| Keskiarvo, keskihajonta | Yleensä korkea | Lähtökohtaisesti julkaistavissa, mutta tarkastettava, että tulos kuvaa riittävän isoa joukkoa ja koko kohdejoukko ei saa samaa arvoa. Lisäksi huomioitava, ettei raportoida tunnuslukuja useammasta lähes identtisestä joukosta tai osajoukosta. |
| Indeksit, suhdeluvut, indikaattorit | Matala | Lähtökohtaisesti julkaistavissa, mutta käytetty laskukaava tulee ottaa huomioon. Monimutkaisemman laskukaavan indeksit (esim. Fisher Price) eivät yleensä aiheuta paljastumisriskiä, mutta hyvin yksinkertaisissa laskukaavoissa riski on mahdollinen ja lukujen taustalla tulee olla riittävästi havaintoja. |
| Keskittymisasteet | Matala | Lähtökohtaisesti julkaistavissa, kun tarkasteltavassa joukossa on riittävän monta havaintoa. |
| Korkeamman momentin tunnusluvut (varianssi, kovarianssi, huipukkuus, vinous) | Matala | Lähtökohtaisesti julkaistavissa, koska tunnusluku on selvästi muunnettu alkuperäisistä yksilön arvoista. Varmistettava, ettei julkaista pienestä joukosta liian montaa tunnuslukua, joiden avulla koko joukko voisi paljastua. |
| Kuviot: alkuperäisen aineiston kuvallinen esittäminen | Yleensä korkea | Kts. tarkemmat huomiot osiosta Kuviot. |
| Korrelaatiot ja regressiotyyppiset analyysit | ||
| Regressiokertoimet | Matala | Lähtökohtaisesti julkaistavissa. |
| Estimoinnin residuaalit | Yleensä korkea | Residuaalit viittaavat yhteen havaintoon, joten aiheuttaa paljastumisriskin. Kts. tarkemmat huomiot osiosta Kuviot. |
| Estimaattien yhteenveto- ja testisuureet (t, F, R2, χ2 etc.) | Matala | Lähtökohtaisesti julkaistavissa, kun tarkasteltavassa joukossa on riittävän monta havaintoa. |
| Korrelaatiokertoimet | Matala | Lähtökohtaisesti julkaistavissa, kun tarkasteltavassa joukossa on riittävän monta havaintoa. |
| Faktorianalyysi | Matala | Lähtökohtaisesti julkaistavissa, mutta varmistettava, ettei faktorien taustalla ole vain yksittäinen muuttuja. |
| Pääkomponenttianalyysi | Matala | Pääkomponenttivektorit ja niitä vastaavat ominaisarvot lähtökohtaisesti julkaistavissa. Havaintojen projektiot pääkomponenteille tarkastettava, koska vastaavat sirontakuviota. Kts. tarkemmat huomiot osiosta Kuviot. |
| Korrespondenssianalyysi | Matala | Lähtökohtaisesti julkaistavissa. |
Joukko tai kohdejoukko tarkoittaa niitä havaintoja, joista tunnuslukuja lasketaan.
Kuviot
Lähtökohtaisesti kuvioiden tietosuojan arvioinnissa aggregoitu taulukkomuotoinen esitys on helpommin hahmotettavissa kuin itse kuvio, koska kuviosta on yleensä mahdotonta nähdä jokaisen pisteen tai käyrän taustalla olevien havaintojen frekvenssejä. Tarvittaessa kuvion mukana tulee toimittaa tuloksen takana oleva taulukko, jos kuviossa kuvataan yksittäisiä havaintoja tai pientä kohdejoukkoa.
Klikkaa otsikoita lukeaksesi lisää tulostyypeistä.
Jakaumakuviot, histogrammi
Jakaumakuvioissa tulee kiinnittää erityisesti huomiota poikkeaviin havaintoihin, jotka voivat aiheuttaa paljastumisriskin. Tämä voi tuottaa haasteen erityisesti esimerkiksi normaalijakauman häntiin, jolloin on mahdollista, että koko häntää ei voida kuvata. Histogrammeissa tulee kiinnittää huomio siihen, että aineisto on luokiteltu niin, että yksittäiseen luokkaan tulee riittävästi havaintoja. Ohje on verrannollinen aineistoa kuvailevien tunnuslukujen tapaukseen.
Pylväsdiagrammi
Pylväsdiagrammeissa tulee kiinnittää huomio siihen, että kuhunkin luokkaan tulee riittävästi havaintoja. Ohje on verrannollinen aineistoa kuvailevien tunnuslukujen tapaukseen.
Hajontakuvio, sirontakuvio
Hajontakuvioissa yhden pisteen taustalla on lähtökohtaisesti yksi yksikkö, minkä vuoksi niitä ei voi julkaista ilman kuvaajan tuottamiseen käytetyn aineiston ryhmittelyä siten, että yhden pisteen taustalla on useampia havaintoja.
Hajontakuvio on julkaistavissa vain, jos sen perustana oleva data täyttäisi anonymiteettivaatimukset myös taulukkomuodossa. Arvioinnissa on kuitenkin huomioitava, mahdollistaako käytettyjen muuttujien yhdistelmä yksilön tunnistamisen.
Hajontakuvion anonymiteettiä voi parantaa korvaamalla se kuvaajalla, jossa esitetään havaintojen frekvenssiä ruudukon soluissa, tai lisäämällä pisteisiin satunnaisuutta.
Viiksilaatikko, laatikkojanakuvio (Box plot)
Viiksilaatikot aiheuttavat lähtökohtaisesti paljastumisriskin, koska ne sisältävät yksittäiseen havaintoon kohdistuvia kuvapisteitä. Erityisesti poikkeaviin havaintoihin voi kohdistua paljastumisriski. Myös keskiarvon julkaiseminen voi aiheuttaa paljastumisriskin. Viiksilaatikkoihin sovelletaan samoja ohjeita kuin aineistoa kuvaileviin tunnuslukuihin.
Residuaalit
Residuaalit viittaavat yhteen havaintoon. Residuaalien kuvaamisessa tulisi käyttää kuvaajan muotoa yksittäisiin pisteisiin perustuvan kuvaajan sijasta. Jos käytetään yksittäisiin pisteisiin perustuvaa kuvaajaa, tulisi akseleiden arvojen esittämistä välttää.
Elinaika-analyysi, Kaplan-Meier-kuvaaja
Elinaika-analyysin paljastumisriski riippuu analyysin määrityksestä. Lähtökohtaisesti tulokset ovat julkaistavissa, jos jokainen kuvaajan askel vastaa riittävän montaa havaintoa. Yksittäisiäkin askeleita voidaan sallia, jos on selvää, ettei kuvaajan taustalla olevien tietojen avulla voida päätellä täsmällisiä ikiä tai kalenteriajan hetkiä. Näissä tapauksissa on kuitenkin arvioitava, kuinka hyvin kuvaajan taustatiedot yksilöivät henkilöitä
Kts. Esimerkki 3.
Spatiaalinen analyysi
Spatiaalinen analyysi on tietosuojan kannalta erityisen haastava, koska sijaintitieto on usein keskeinen tieto yksilön tunnistamisen kannalta. Spatiaalisen analyysin tulosten julkaiseminen edellyttää yleensä sijaintitiedon uudelleenluokittelua ja esittämistä lämpökarttoina yksittäisten havaintopisteiden sijaan.
Sankey-kuvaajat
Sankey-kuvaajien eli virtausdiagrammien tietosuojaan vaikuttaa se, mitä tietoa kuvaajassa esitetään. Jos kuvaaja sisältää tarkkoja lukumääriä, siihen sovelletaan samoja ohjeita kuin aineistoa kuvaileviin tunnuslukuihin.
Kts. Esimerkki 4.
Muut tulostyypit
Klikkaa otsikoita lukeaksesi lisää tulostyypeistä.
Kuvat ja muut kuvantamisen materiaalit
Kuvantamisen materiaalien tietosuojariski arvioidaan tapauskohtaisesti. Materiaaleissa ei saa olla yksittäiseen henkilöön viittavia tunniste- tai metatietoja. Tunnistamisriskiä voidaan vähentää esimerkiksi rajauksilla ja resoluution alentamisella. Jos kuvantamisen materiaaleihin voidaan yhdistää muuta tietoa, tämä lisää tunnistamisen riskiä.
Lisätietoja kuva- ja signaalitietojen anonymisoinnista löytyy STM:n korkean tason asiantuntijaryhmän periaatelinjauksesta: Kuva- ja signaalitiedon anonymisointi ja anonymiteetti sosiaali- ja terveystietojen toissijaisesta käytöstä annetun lain (522/2019) mukaisessa käsittelyssä (stm.fi, PDF-tiedosto, 248 kb)
Genomitietoon perustuvat tulokset
Genomitietoon perustuvien tulosten anonymiteetti arvioidaan aina tapauskohtaisesti.
1. Harvinaiset yksittäiset geneettiset variaatiot
Merkittävien harvinaisten geneettisten löydösten julkaiseminen on lähtökohtaisesti mahdollista, jos löydös esiintyy vähintään kolmella tutkittavalla. Jos geneettinen variaatio ilmenee alle kolmella tutkittavalla, tulee tarkka määrätieto esimerkiksi peittää.
Tuloksia julkaistaessa tulee kiinnittää erityistä huomiota tutkittavien tunnistettavuuteen ja arvioida tapauskohtaisesti, riittääkö minimifrekvenssin n=3 käyttäminen estämään tutkittavien tunnistamisen. Mitä pienempää kohdejoukkoa tutkitaan ja mitä enemmän tutkittavista kerrotaan taustatietoa, esimerkiksi sairauden ilmiasusta (fenotyypistä), tai maantieteellisestä alueesta, jolta tutkittavien kohdejoukko on kerätty, tutkittavien tunnistettavuus lisääntyy merkittävästi.
Yksittäisistä tutkittavista ei saa julkaista
- tarkkaa ikää,
- tarkkaa kuvailua tutkittavan ilmiasusta,
- sairaushistoriaa,
- tarkkaa maantieteellistä aluetta, jolta tutkittavat on kerätty tai
- muuta tietoa, joka vaarantaa tutkittavien anonymiteetin.
Geneettisten variaatioiden ominaisuuksista kertovat tiedot voidaan julkaista, jos kyseiset tiedot löytyvät jo julkisista varianttitietokannoista, kuten:
- alleelin frekvenssitiedot,
- variantin kliininen merkittävyys,
- variantin identifioiva rs-numero, tai
- tutkimusmenetelmä, jolla geneettinen löydös on havaittu.
Harvinaiset geneettiset löydökset voidaan julkaista esimerkiksi taulukon 2 mukaisesti.
| Causal gene | Disorder | Patient N | Zygosity of variant | Reference transcript | DNA variant | Protein variant | Molecular consequence | Pathogenicity classification | db SNP ID | gnomAD MAF, European | gnomAD MAF, Finnish | SpliceAI | phyloP | CADD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EPHA2 | Lung cancer | <3 | Heterozygous | NM_004431.5 | c.1171G>C | p.Gly291Arg | missense variant | Likely pathogenic | rs34192549 | 0.01679 | 0.00947 | 0.0100 | 0.135 | 6.37 |
| NRAS | Lung cancer | 5 | Heterozygous | NM_002524.5 | c.183A>C | p.Gln61His | missense variant | Pathogenic/Likely pathogenic | rs121913255 | NA | NA | NA | NA | NA |
| DDR2 | Lung cancer | <3 | Heterozygous | NM_006182.4 | c.716T>G | p.Leu239Arg | missense variant | Likely pathogenic | rs578015216 | 0.000 | 0.000 | 0.000 | 6,32 | 24.5 |
2. Geneettiset variaatiot, jotka eivät esiinny tutkittavan omassa perimässä
Aikaan sidoksissa olevat geneettiset mutaatiot, jotka eivät esiinny tutkittavan omassa perimässä vaan ilmenevät esimerkiksi syöpäkasvaimessa, voidaan julkaista potilaskohtaisesti.
Tuloksia julkaistaessa tulee kuitenkin kiinnittää erityistä huomiota yksittäisten henkilöiden tunnistamisriskiin. Yksittäisistä henkilöistä ei voi julkaista
- tarkkaa ikää,
- tarkkaa kuvailua henkilön ilmiasusta,
- sairaushistoriaa,
- tarkkaa maantieteellistä aluetta, jolta kohdejoukko on kerätty tai
- muuta tietoa, joka vaarantaa henkilön anonymiteetin.
Mikäli mutaatioita tai henkilöitä on mahdollista luokitella ryhmiin, tulee tulokset esittää ensisijaisesti tässä muodossa.
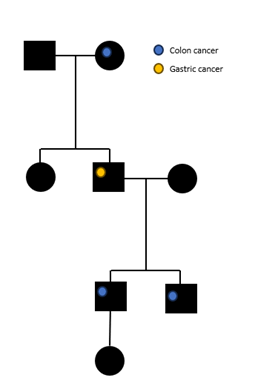
3. Sukututkimukset
Tuloksia julkaistaessa tulee kiinnittää erityistä huomiota suvussa esiintyvien henkilöiden anonymiteettiin. Sukututkimuksissa ilmenevät periytyvät geneettiset muutokset voidaan julkaista ja esittää esimerkiksi sukupuuna kuvion 1 mukaisesti.
Sukupuussa esiintyvistä henkilöistä ei saa esittää muuta tarkkaa taustatietoa, kuten
- ikää,
- ajankohtaa, jolloin geneettiset muutokset on löydetty,
- maantieteellistä aluetta, jolta sukuhistoria on kerätty tai
- muuta tietoa, joka vaarantaa suvun anonymiteetin.
Mitä enemmän tietoa yksittäisistä henkilöistä kuvassa kerrotaan, sitä suuremmaksi paljastumisriski kasvaa. Hyvin harvinaisten sairauksien kohdalla on mahdollista, että sukupuuta ei voida julkaista anonyymissa muodossa.
Tekoäly- ja koneoppimismallit
Jos tekoäly- tai koneoppimismalli/algoritmi itsessään on tutkimuksen julkaistava tulos, sen anonymiteettiin tulee kiinnittää huomiota jo kehitysvaiheessa. Mallin anonymiteetti tulee voida todistaa, jotta se voidaan julkaista. Jokaisen mallin anonymiteetti arvioidaan tapauskohtaisesti.
Kun malli toimitetaan anonymiteetin tarkastukseen, Findatalle tulee toimittaa myös tekoäly- ja koneoppimismallien anonymiteettilomake. Lomakkeeseen kannattaa tutustua huolellisesti jo mallin suunnitteluvaiheessa, jotta anonymiteettiin vaikuttavat tekijät voidaan huomioida jo kehitysvaiheessa.
Lataa lomake: Tekoäly- ja koneoppimismallien anonymiteettilomake (Word-tiedosto, 50,1 kt)
Anonymiteettiin vaikuttavat tekijät:
- Mallin ominaisuudet, kuten mallin tyyppi ja opetettavien parametrien määrä
- Mallin opetukseen käytetyn aineiston piirteet, kuten sen määrä, sisältö, muoto ja mahdollinen käsittely kuten anonymisointi
- Mallin yleistämiskyky ja suoriutuminen tehtävästä, jota varten se on koulutettu.
Jos mallia on koulutettu käyttäen ainoastaan anonyymia opetusmateriaalia, myös itse mallin voidaan katsoa olevan anonyymi.
Mallin anonymiteetti voidaan varmistaa käyttämällä sen koulutuksessa differentiaalista tietosuojaa. Käytettyjen differentiaalisen tietosuojan parametrien valintaan ei ole yksiselitteisiä ohjeita, vaan ne tulee määritellä tapauskohtaisesti ja valinta on perusteltava.
Pienet arvot kuten
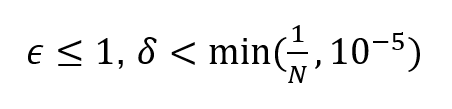
missä N on yksilöiden lukumäärä käytetyssä aineistossa, tuottavat matemaattisesti vahvan suojan, mutta tapauksesta riippuen myös suuremmat arvot saattavat riittää.
Pääsääntöisesti mallin opetusmateriaaliin ei tulisi sisällyttää aineistoa, joka sisältää yksilötasoisia suoria tunnisteita. Malli, jonka parametreihin on sisällytetty yksilöön viittaavia tietoja ymmärrettävässä muodossa (esimerkiksi tekstinä), ei täytä anonymiteetin kriteereitä. Mallin kehitysprosessissa tulee huomioida riittävät toimet mallin yleistämiskyvyn arviointiin.
Yksilötasoinen aineisto
Julkaistavien tulosten tulee lähtökohtaisesti pohjautua useampaan havaintoon. Jos on tarve julkaista tulosaineistoa, joka on kokonaisuudessaan yksilötasoista, sen tulee täyttää anonyymin tiedon määritelmä (kts. Mitä anonymisointi tarkoittaa?).
Yksilötasoisen anonyymin aineiston tuottamiseen tarvitaan yleensä kehittyneitä menetelmiä, kuten differentiaalista tietosuojaa. Yksilötasoisen aineiston anonymiteetti on aina varmistettava tapauskohtaisesti.
Synteettinen tulosaineisto
Synteettisen aineiston anonymiteettiin vaikuttavat:
- Syntetisointimenetelmä
- Pohja-aineiston ominaisuudet, jos synteettinen aineisto on tuotettu henkilötietoaineistosta
Se, että julkaistava aineisto on synteettistä, ei yksin riitä takaamaan sen anonymiteettiä. Anonymiteetin varmistaminen riippuu aineiston tuottamismenetelmästä ja sen monimutkaisuudesta. Jos tarkoituksena on muodostaa anonyymia synteettistä dataa, anonymiteetin varmistaminen on huomioitava jo prosessia kehittäessä.
Synteettisen tulosaineiston anonymiteetti tulee aina varmistaa tapauskohtaisesti.
Laadullisen tutkimuksen tulokset
Laadullisilla tutkimusmenetelmillä tuotettujen tulosten tulee täyttää anonyymin tiedon määritelmä.
Jos mahdollista, julkaistavissa tuloksissa tulisi käyttää minimifrekvenssiä kolme tietosuojan varmistamiseksi. Jos tämä ei ole mahdollista, tulokset tulee käsitellä niin, ettei yksittäistä henkilöä voi tunnistaa suoraan tai välillisesti.
Kohdejoukon muodostamismenetelmä vaikuttaa tunnistamisriskiin. Tunnistamisriski on suurempi, jos kohdejoukko sisältää kaikki tietyt kriteerit täyttävät henkilöt verrattuna tilanteeseen, jossa kohdejoukko on satunnaisesti tai otannalla valikoitunut.
Erityisesti tekstilainausten julkaisemisen yhteydessä on huomioitava, ettei lainaus mahdollista yksittäisen henkilön tai tapahtuman tunnistamista. Tunnistamisriski kasvaa, jos lainaus sisältää yksittäistä henkilöä tai tapahtumaa koskevia yksityiskohtia, tai koskee harvinaista ilmiötä.
- Laadullisen aineiston anonymisoinnista ja anonymisointimenetelmistä löytyy lisätietoa Tietoarkiston sivuilta: Laadullisen aineiston anonymisointi (fsd.tuni.fi).
- Kts. esimerkki 5
Esimerkkejä ohjeen soveltamisen tueksi
Esimerkki 1. Frekvenssitaulukko ja toissijainen paljastuminen
Frekvenssitaulukossa solun tietojen tulee pohjautua vähintään kolmeen havaintoon. Jos havaintojen määrä on tätä pienempi, tulee tarkka lukuarvo peittää. Alle kolmeen havaintoon viittaavan tiedon voi peittää esimerkiksi merkinnällä ”<3”.
Peitettyä arvoa ei tule pystyä laskemaan auki taulukon muiden lukujen avulla. Jos taulukon muiden lukujen avulla pystyy päättelemään peitetyn frekvenssin tarkan arvon, tulee myös muita lukuja peittää.
Esimerkki 1.1.
Alla olevassa taulukossa solussa Vuosi 3 on alle kolmeen henkilöön pohjautuva havainto, joka tulee peittää.
| Vuosi 1 | Vuosi 2 | Vuosi 3 | Kokonaismäärä | |
| Ryhmä a, n | 0 | 12 | 1 | 13 |
Pelkkä pienen havaintoarvon peittäminen ei kuitenkaan riitä, sillä muiden lukuarvojen avulla pystyy laskemaan sen tarkan arvon auki. Pienen havaintoarvon auki laskemisen voi estää karkeistamalla kokonaismäärän tai toisen havaintoarvon tarkan lukuarvon alla olevan mukaisesti. Tällöin solujen Vuosi 2 ja Kokonaismäärä avulla pystytään päättelemään, että Vuosi 3 -solu voi saada arvoksi 1 tai 2, mutta tarkkaa arvoa ei tiedetä.
| Vuosi 1 | Vuosi 2 | Vuosi 3 | Kokonaismäärä | |
| Ryhmä a, n | 0 | 12 | <3 | 13–14 |
| Vuosi 1 | Vuosi 2 | Vuosi 3 | Kokonaismäärä | |
| Ryhmä a, n | 0 | >10 | <3 | 13 |
Lukuarvoa nolla ei tarvitse lähtökohtaisesti peittää, sillä kyseinen tieto ei viittaa keneenkään yksittäiseen henkilöön.
Esimerkki 1.2.
Alla olevassa taulukossa on kahdessa solussa alle kolmeen henkilöön pohjautuva havainto (n=1), jotka molemmat tulee peittää.
| Vuosi 1 | Vuosi 2 | Vuosi 3 | Kokonaismäärä | |
| Ryhmä b, n | 1 | 3 | 1 | 5 |
Vaikka molemmat havaintoarvot peitettäisiin merkinnällä <3, on solujen Vuosi 2 ja Kokonaismäärä avulla kuitenkin pääteltävissä, että molempien peitettyjen solujen arvo on 1. Tässä tapauksessa pienten havaintoarvojen auki laskemisen voi estää esimerkiksi peittämällä kaikki kolme havaintoarvoa merkinnällä ≤3.
| Vuosi 1 | Vuosi 2 | Vuosi 3 | Kokonaismäärä | |
| Ryhmä b, n | ≤3 | ≤3 | ≤3 | 5 |
Tilanne olisi toinen jos kokonaismäärä olisi esimerkiksi 6 (kuten alla olevan esimerkin 1.3. taulukossa). Tällöin <3-merkinnällä peitetyistä kahdesta solusta ei olisi pystynyt päättelemään kumpi saa lukuarvon 1 ja kumpi lukuarvon 2.
Esimerkki 1.3.
Alle kolmeen henkilöön pohjautuvat havainnot voivat paljastua myös suhteellisten osuuksien avulla. Vaikka alla olevasta esimerkistä peitettäisiin pienet frekvenssit merkinnällä <3, on suhteellisten osuuksien ja kokonaismäärän avulla mahdollista laskea auki solujen Vuosi 1 ja Vuosi 2 tarkat arvot.
| Vuosi 1 | Vuosi 2 | Vuosi 3 | Kokonaismäärä | |
| Ryhmä c, n | 1 | 3 | 2 | 6 |
| Ryhmä c, % | 17,7 | 50 | 33,3 | 100 |
Tässä tapauksessa siis myös suhteelliset osuudet tulee peittää.
| Vuosi 1 | Vuosi 2 | Vuosi 3 | Kokonaismäärä | |
| Ryhmä c, n | <3 | 3 | <3 | 6 |
| Ryhmä c, % | ≤33 | 50,0 | 17–33 | 100 |
Esimerkki 2. Minimi ja maksimi
Minimi- ja maksimiarvot kohdistuvat yleensä yksittäiseen havaintoon, joten ne voivat sisältää paljastumisriskin erityisesti niissä tapauksissa, kun ryhmän koko on pieni ja/tai yksittäiset havainnot ovat hyvin poikkeavia. Minimi- ja maksimiarvot voidaan julkaista, jos tunnusluvun arvo perustuu useampaan havaintoon tai yksilön paljastumisriski voidaan estää muulla tavoin.
Esimerkiksi esitettäessä tunnuslukuja tutkittavien pituudesta, voivat poikkeuksellisen lyhyet tai pitkät henkilöt erottua joukosta kasvattaen yksilön paljastumisriskiä. Alla olevan taulukon mukaisessa ryhmässä, jossa keskipituus on 168 cm, erottuu 195 cm mittaisen henkilön lukuarvo poikkeuksellisena joukosta. Poikkeuksellisia ominaisuuksia omaavat henkilöt jäävät helposti myös ihmisten mieleen, jolloin kyseisen henkilön paljastumisriski on suurempi.
| Pituus, cm | |
| Henkilö 1 | 162 |
| Henkilö 2 | 162 |
| Henkilö 3 | 170 |
| Henkilö 4 | 157 |
| Henkilö 5 | 195 |
| Henkilö 6 | 166 |
| Henkilö 7 | 171 |
| Henkilö 8 | 164 |
Tulosten anonymiteettiä voi parantaa jakamalla tiedot luokkiin, jolloin jokaiseen luokkaan tulee useampia yksilöitä. Minimin ja maksimin rinnalla voi harkita sopivien kvantiilien käyttöä.
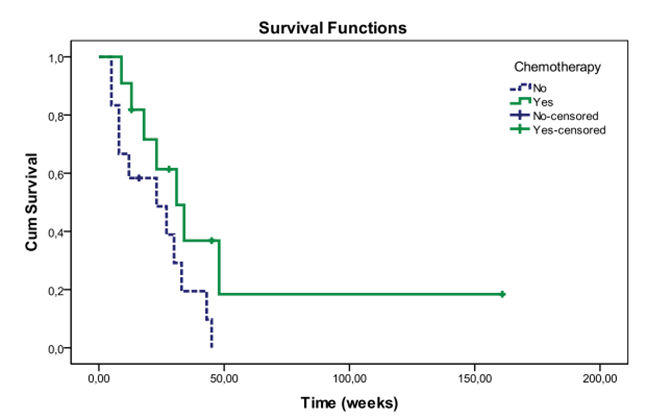
Esimerkki 3. Kaplan Meier -kuvaaja
Kaplan-Meier-kuvaajan ja sen tausta-aineiston voi julkaista, jos kuvaajan taustalla olevien tietojen avulla ei voida päätellä täsmällisiä kalenteriajan hetkiä tai yksittäisten henkilöiden ominaisuuksia, kuten ikää. Tällöin kuvaajassa voidaan sallia yksittäisiäkin askeleita.
Kuvion 2 kuvaajan voi julkaista, koska sen perusteella ei voi tunnistaa yksittäisiä henkilöitä eikä päätellä täsmällisiä kalenteriajan hetkiä.
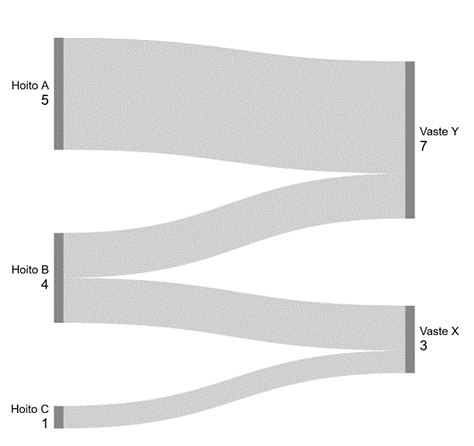
Esimerkki 4. Sankey-kuvaaja
Jos Sankey-kuvaaja kuvaa tarkkoja lukumääriä, tulee tuloksissa huomioida minimifrekvenssi. Kuvion 3 tietoja ei voi julkaista ilman anonymisointia, kuten uudelleen luokittelua, koska kuviosta tulee esille tarkat n< 3 frekvenssit.
Esimerkki 5. Yksilötasoinen aineisto ja laadullinen tutkimus
Lähtökohtaisesti anonyymien tulosten tulee pohjautua useampaan havaintoon. Tämä koskee myös laadullisia tutkimuksia. Jos on kuitenkin tarve julkaista yksilötasoista tulosaineistoa, tulee tulokset käsitellä niin, ettei tulosaineistosta voi tunnistaa yksittäistä henkilöä.
Erityisesti tekstilainauksissa tunnistamisriski kasvaa, jos lainaus sisältää yksittäistä henkilöä tai tapahtumaa koskevia yksityiskohtia, tai koskee harvinaista ilmiötä. Alla olevassa kuvitteellisessa tekstilainauksessa on potilaan nimen lisäksi paljon muutakin yksilöivää tietoa.
13-vuotias Eero Esimerkki tuotiin hoidettavaksi Turun yliopistolliseen keskussairaalaan hänen kaaduttuaan Turun Yhteiskoulun pihassa. E.E. sairastaa hemofilia A:ta. E.E:n tutkinut gastroenterologi teki lähetteen…
Tekstilainauksissa yksityiskohtia voi peittää kategorisoimalla, jolloin tunnistamisriskiä saadaan pienennettyä.
[Yläkouluikäinen] [potilas] tuotiin hoidettavaksi [yliopistolliseen keskussairaalaan] hänen kaaduttuaan [koulunsa] pihassa. [Potilas] sairastaa [vaikeaa pitkäaikaissairautta]. [Potilaan] tutkinut [lääkäri] teki lähetteen…
Anonyymien tulosten tuottajan tarkastuslista
| Tehty ✓ | |
| Olen lukenut Findatan anonyymien tulosten tuottaminen -ohjeen. | |
| Tulokset täyttävät anonyymin tiedon määritelmän. | |
| Tulokset eivät sisällä suoria tunnisteita (esim. nimi, henkilötunnus). | |
| Tulokset eivät sisällä vahvoja, epäsuoria tunnisteita (esim. osoite, rekisteröintinumero). | |
| Tulokset eivät sisällä pseudotunniste-koodeja (esim. Findatan FID). | |
| Tulokset eivät sisällä solukohtaisia frekvenssejä n< 3. Jos tulokset sisältävät solukohtaisia frekvenssejä n< 3, olen perustellut tulosten anonymiteetin. | |
| Jos pieniä frekvenssejä on peitetty, peitettyjä arvoja ei voi päätellä muiden tulosten avulla. | |
| Tulokset eivät sisällä yksilötasoista tai yhteen henkilöön viittaavaa tietoa (esim. minimi, maksimi). Jos tulokset sisältävät tällaista tietoa, olen perustellut tulosten anonymiteetin. | |
| Olen arvioinut tulosten anonymiteetin erityistä huolellisuutta käyttäen, jos tulokset sisältävät: Tekoäly/ koneoppimismallin Kuvia tai muuta kuvantamisen materiaalia Geneettistä tai genomitietoa Synteettistä tulosaineistoa | |
| Olen tarkistanut, että tulostiedostojen taustalle ei ole jäänyt piiloon aineistoa. Olen kiinnittänyt erityistä huomiota R-tiedostoihin (.rda, .rdata, .rds, .rdm), kuvantamismateriaalien metadataan, Pythonin Jupyter notebookeihin (.ipynb) sekä Excelin piilotettuihin välilehtiin. |
Lähteet
- Brandt et al. (2009): Guidelines for the checking of output based on microdata research (PDF-tiedosto,
755 kt) - European Data Protection Board: Opinion 28/2024 on certain data protection aspects related to the processing of personal data in the context on AI models (edpb.europa.eu)
- Green, E. et al. (2020). Understanding output checking (PDF-tiedosto, 1 121 kt)
- Griffiths, E. et al. (2019). Handbook on Statistical Disclosure Control for Outputs, version 1.0. 2019.
- Hundepool, Anco; Domingo-Ferrer, Josep; Franconi, Luisa; Giessing, Sarah; Schulte-Nordholt, Eric; Spicer, Keith & de Wolf, Peter-Paul (2012). Statistical Disclosure Control.
- Ponomareva et al. (2023). How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy. Journal of Artificial Intelligence Research Vol. 77, 2023.
- SankeyMATIC, 2024 (sankeymatic.com)
- Sosiaali- ja terveysministeriö: Pseudonymisointi, anonymisointi ja suorien tunnisteiden käyttö Sosiaali- ja terveystietojen toissijaisesta käytöstä annetun lain (522/2019) mukaan (PDF-tiedosto, 418 kt).